Summary ¶
企業のネットが星を被い、電子や光が駆け巡ってもハイパーバイザーやデータが消えてなくなるほど、情報化されていない近未来。
VMware の社内利用を禁じられた企業ネットでは新しい仮想化基盤を構築するべく自宅環境をクローンするのであった。
シリーズで記事にするつもりはなかったが、 Cluster を作成する前の段階で 14k 字を超えているためパケット分割しお届けする。今回では Proxmox VE の構成するにあたり知識として知っておきたいこと、物理構成のサンプルなどを紹介する。





Proxmox VE とは ¶
Proxmox Server Solutions GmbH. が開発し提供している Proxmox Virtual Environment (以下 PVE) を主軸とする仮想化基盤の中では歴史が古く 2009 年には PVE Ver 0.9 をリリースし今日まで継続して開発されている。
機能としては商用製品に引けを取らない充実の機能で弊宅でも 2019 年ごろから利用している。HCI 構成を得意としていて、それなりのスペックの Server 3 台と Switch 2 台を用意できれば共有ストレージなどがなくても利用可能。
HCI(Hyper-Converged Infrastructure) として稼働でき少ないリソースでスタートが可能。クラスターに参加できる最大目安は 32 台となっているためそれを超える場合はサイジングが必要になると思われる。
主な機能は下記。
- KVM ベースの仮想環境
- LXC 環境
- WebGUI による統合的な利用
- クラスタリング
- 最小 3 台のサーバーを所属させることで下記の機能が使える
- Live/Online Migration
- Cpeh による分散ストレージ
- 2/3 台のサーバーが生きていればサービスを継続できる
- HA 機能
- HA することでハイパーバイザー障害も自動的に復旧が可能
- 最小 3 台のサーバーを所属させることで下記の機能が使える
- バックアップ
- Proxmox Backup Server とネイティブに連携して増分バックアップが可能
- SMB/CIFS, NFS などを利用して Disk Image をまるまるバックアップ保存することも可能
など、非常に多くの機能があるので抜粋詳細は公式ページを参照するとよい。
物理構成 ¶
早速ですが、明日(執筆時点)社内検証環境を構築せなにゃならんので弊宅で予習も兼ねて Proxmox VE on Proxmox VE でテストします。通常であれば最小構成で下記の機材が必要です。
| Role | 台数 | サービス | mgmt | その他 |
|---|---|---|---|---|
| Firewall | 2 | 2 | 2 | HA用 2 |
| Core Switch | 2 | 5 | 2 | Peer-to-Peer 2 |
| MGMT Switch | 1 | 12 | 1 | |
| Server | 3 | 2 | 1 | 余裕があるなら StorageNW を分けるで +2 |
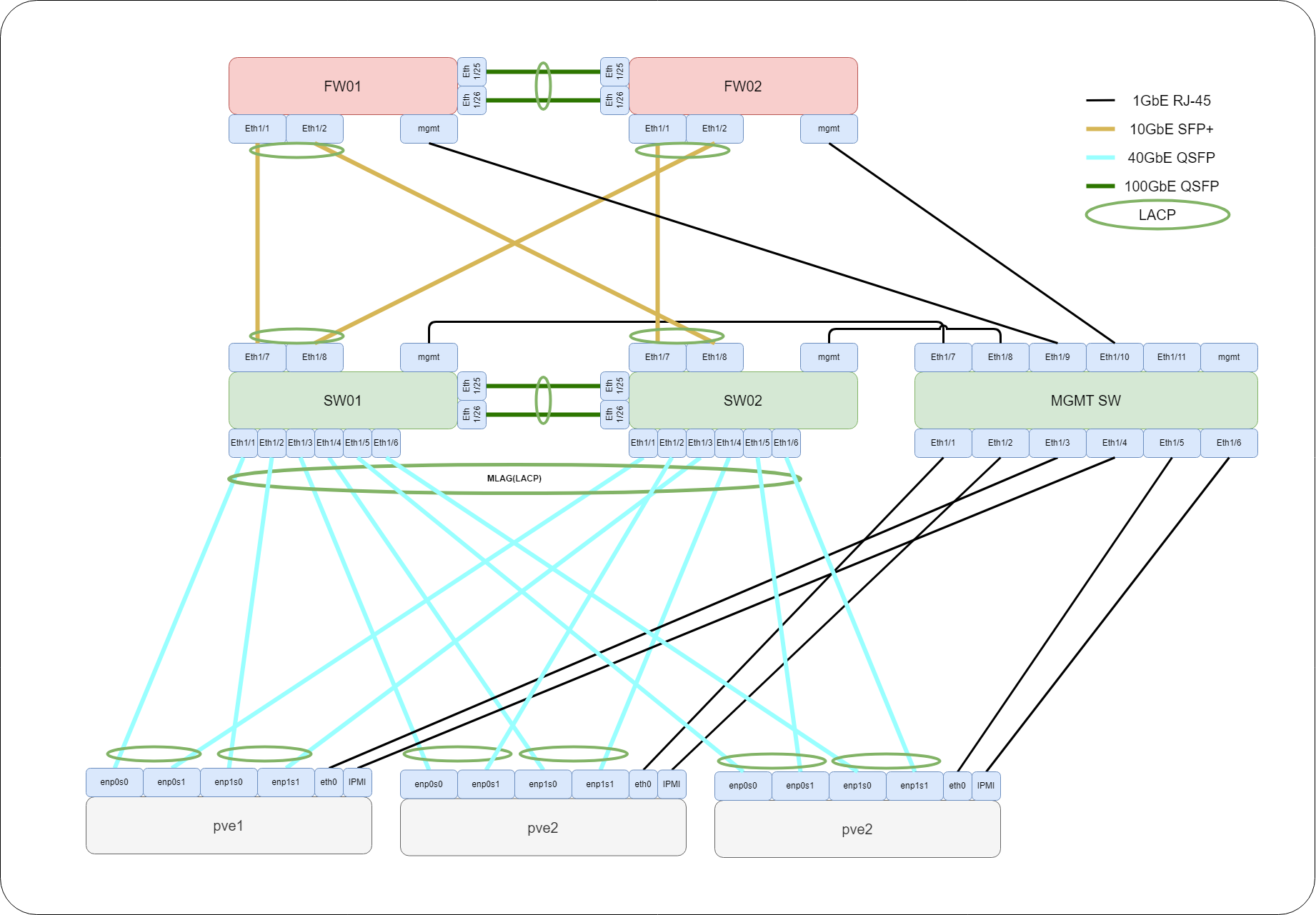
Firewall 2台 ¶
- Trunk VLAN を受けて NAT とルーティングができれば良い
- 今後の構成変更に耐えるように見据えるのであれば Dynamic Routing に対応しているか確認しておく
- 大規模化する場合 EVPN-VXLAN を利用して基盤を大きく、L2 延伸する場合があり BGP で Server まで経路交換することになるので BGP が対応していると安心
Core Switch 2台 ¶
- MLAG(Multi-Chassis Link-Aggregation) ができるとよい
- 出来ない場合は L2 冗長を諦め、 Active-Stanby などを取る必要がある
- Peer-to-Peer は 40GbE 程度の冗長リンク
- 可能なら 10GbE 以上は光ケーブルで接続する
- DAC/AOC などで構成も可能。 Copper ケーブルは太く Switch に大量に接続することになるため取り回しの問題や重量で Switch Port に経年故障が出る可能性あり。
- また Copper ケーブルは曲げによる減衰が発生する場合もあり(光ほど顕著に出ないので気づきにくい)運用数年後に原因不明のトラシューとなる可能性
- Server, Firewall は少なくとも 10GbE で 2 本ずつ接続し LACP する
- これは運用省力化するのに必要
- LACP ではリンク状態も確認でき MLAG であれば Link Speed が 20 Gbps に見える状態となり簡単に増速する手にもなる
- Core Switch のメンテナンスでかた系 down とした場合に完全に接続断とはならないため縮退でサービスを維持が可能
- 冗長化の方法はいくつかありますが個人的には LACP がこなれていると感じている
- 通常であれば必要無いが Jumbo MTU を設定する場合もあるため最大 MTU を確認
- 対応している最大 VLAN 数を確認 (VLAN 32 個まで等の制約がある)
- 対応している最大 LACP 数を確認 (LACP グループ 8 個まで等の制約がある)
MGMT Switch 1台 ¶
- 少なくともこの構成の MGMT を収容すると 10 Port はいるため 24Port 程度の Switch があると良いでしょう
- 管理 VLAN を切り Access Port として対向機器に何も設定しなくても Link が上がる状態
- DHCP をするわけではありません、 対向機器が VLAN などの設定をしなくても繋がることが重要
Server 3台 ¶
- Xeon などの多コアで DIMM が多く、メモリーチャンネル数が稼げる物
- OS ストレージについて
- OS は 256GB 以上の SSD/NVME ストレージを用意する必要があり
- 256GB はあくまで私信ですが PVE は HCI として利用する場合はかなりのログを絶えず吐き続けるため低用量の SSD では TBW が足りず、すぐ故障するため。
- 通常インストールの場合 LVM が作成され Disk 全体の 1/4 で root disk で作成
- 256GB であれば 64GB 程度が割り当てられる
- Data 用ストレージ
- SSD が望ましいですが、 HDD でも可
- 最低 1 つの Disk が搭載されている必要があり
- どの Server でも同じ容量のストレージが求められる
- コンシューマー向け SSD ではキャッシュメモリーや NAND の構造で速度が出なかったり刺さる(I/O が止まる現象)の可能性がある
- エンタープライズの SSD はスーパキャパシターなどが内蔵されていて電源断でもメモリー内のデータを書き込む時間が作れる
- Ceph の I/O Size は手元で 16kB になっているため 1000 IOPS を仮想マシンに提供すると約 15.62MB/s になります
- Ceph は最小 3 台で構築し書き込み処理は Secondary Disk に書き込みが完了するのを待つため理論的には NIC を経由して残り 2 台の Disk に書き込めるまで待機する。
- 絶えず O/I が出るわけでは無いので大まかにサイジングプランとして SSD の性能で割ると
- SATA 550MB/s 35 台
- NVME Gen3x4 2,900MB/S 185 台
- このパフォーマンスを求めるならネットワークも 25GbE が必要
MGMT は分けるべし ¶
これから構築する PVE はクラスター管理として RHEL 系を利用したことある方なら馴染がある、 Corosync を利用しています。そのため HeartBeat の通信が通常であれば vmbr0 を通ってクラスター間で死活を監視します。
この通信が阻害される場合、クラスターは Node 再起動などあらゆる手段を実施して復旧させようとします。そのためこの通信が LACP や bond0, vmbr0 を経由した通信で NIC と相性が悪いなど条件が重なるとクラスターの半壊等が多発する状況となり可用性に直結しますので、専有の NIC を割り当てるべきです。
Corosync のネットワークはリダンダント(サブ経路設定できる)できるため、その場合は ensXX などの物理と LACP などをした vmbr0 を含めても安定する。順番に利用されるため、割り当てた専用 NIC にアクセス出来ない場合のみ利用される。
また、 MGMT を分ける意味はもう 1 つあります
Proxmox VE のネットワーク設定は /etc/network/interfaces で管理されいます。
専用 Interface にすることで LACP やサービスポートとして利用している変更に失敗してもアクセスが継続できるためです。
Storage NW ¶
今回のように HCI(Hyper-Converged Infrastructure) ユースとなる場合、 Server で ISO 置き場や VM Storage も提供する必要があります。問題になるケースとしてライブマイグレーションで大量の通信をすることで前述のクラスター間通信が輻輳し不安定になることです。
これを回避するために MGMT ネットワークは LACP している回線から外すべきです。また、超低遅延のネットワークが必要になるので QoS などでコントロールするべきでもないかと考えています。
構成上取れない場合は個別に各機能で帯域幅制限も可能なため輻輳しないように設定が必要です。
RAID ¶
おうちえんたーぷらいずな機材たちは RAID Controller を搭載している機器が多い。
ですが Ceph を利用してストレージを作成する場合 RAID をするべきではなく、 HBA モードにするべきです。
HBA モードが設定出来ない場合は Ceph を諦めるか自己責任になりますが単一の RAID0 を台数分設定して逃げる方法もあるようです(完全に自己責任です)
Proxmox VE OS Disk の可用性について気になるが、 ZFS で miror するかそもそもハイパーバイザーの OS なので壊れたら再インストールが無難となります。設定項目は多く無いため弊宅でも故障交換の対応としています。
Domain ¶
Domain とは exsample.com などを指しますが、しっかりと構築するのであれば自社のドメイン名でドメイン設計し構築したほうが認証などの導入障壁は下がる。弊宅ではネットワーク用として .net を取得しているためそこから割当 subdomain を決定しわり当てています。
ない場合は .local や今後承認されるであろう .internal を使うと良い。
ただ、前述の通り認証の絡みで自社ドメイン設定していない場合余分にハマる可能性があることは考慮しておくべきかと思いました。
Hostname ¶
普段何気なく使っている Hostname は正確に規約が設定されており RFC1035 という物です。これにはラベル(一般名ではホスト名)に利用できる文字が定義されていて、これに違反していたため弊宅の構築で、 Ceph Metadata Server が起動せずに Proxmox VE の再インストールを余儀なくされました。
皆さんは設計時に考慮ください
ホスト名で設定できる文字。
- 先頭は文字で始まる、数字はダメ
- ホスト名の中では文字、数字、 ハイフン(
-)しか使えない - 末尾は文字または数字でなければならない
- 63 文字以下
ラベルは ARPANET のホスト名に関するルールに従わなければならない。ラベルは 文字で始まり、文字または数字で終わり、その間には文字、数字、ハイフンだけ しか存在してはならない。長さに関する幾つかの制約も存在する。ラベルは 63 文字以下でなければならない。
― jprs.jp/tech/material/rfc/RFC1035-ja.txt
IP Address ¶
Proxmox VE 8.1 より SDN 機能が搭載され設定をすれば DHCP で IP Address を配り、 SNAT などをして外と通信できるように出来ます。また netbox, phpipmi と連携し既存の IPMI を参照して割り当てなども可能です。
VLAN を作成し個別に DHCP, DNS を生やすのは中々大変のため利用するのもあり。
私個人は近いうちに使ってみて、仮想マシーンに振る IP Address はこちらからアサイン出来たら楽だと考えてます。

Cluster & Hostname ¶
Proxmox VE のクラスターは他の Corosync クラスターと同じように利用されますが、ユーザーが限りなく手を抜けるように様々な工夫がされています。
そのため、クラスターから脱退,加入する Node は再インストールが推奨されています。
クラスターIP を変更する程度なら可能ですが、ホスト名・ドメインの変更は外見的に実施出来ていても内部処理まですべて確認するのは困難であり、対応後の不具合防止の観点からも再インストールが求められます。
Corosync のネットワーク要件は 5ms 以下の低レイテンシーで専有できるネットワークが推奨されます。物理機器を利用して導入テストができる場合は ping などで latency, Jitter が 5ms 以内か確認しておくと良いでしょう。
また、ストレージネットワークとの共存は可能な限り避けるべきと公式ドキュメントに記載があります(フォールバック回線としてはありとも書いてある)
The Proxmox VE cluster stack requires a reliable network with latencies under 5 milliseconds (LAN performance) between all nodes to operate stably. While on setups with a small node count a network with higher latencies may work, this is not guaranteed and gets rather unlikely with more than three nodes and latencies above around 10 ms.
― Cluster Manager
Ceph ¶
詳しくは一度、 Ceph の公式ドキュメントを翻訳でもよいので確認しておくべきです。
ハードウェア ¶
CPU
- Monitor, Manager と OSD 1 つの場合 3 つの CPU スレッド割当が理想、 OSD 2 つの時は 4 CPU スレッド
- NVMe を OSD として利用する場合は 4 ~ 6 個の CPU スレッドが使われるケースもある
Memory
- OSD 1TiB あたり 1GiB のメモリーが最低必要
- OSD の動作によっては 3-5GiB の追加メモリーを消費する瞬間がある
- 例えば、 OSD 5TiB なら 5-25GiB のメモリーは常に空いてる状態が望ましい
Network
- 推奨ネットワーク構成 3 つのネットワークを作る
- 1GbE Management
- Proxmox VE WebGUI
- Proxmox Cluster Heartbeat (Corosync)
- Ceph
Public Network,Cluster Networkは可能なら 1 つの物理カードから 1 本ずつ取って 2 枚刺す- 物理カード障害を耐えることができる
Public NetworkCluster Networkを作成しない場合はすべての通信がここを使う- Monitor
- Manager
- metadata
- Ceph Clients
Cluster Network- OSD Service
- Replication
- Self-balancing
- Self healing
- Heartbeat check
- OSD Service
- 1GbE Management
- 推奨ネットワーク構成 3 つのネットワークを作る
MB/s と Gbps の対比
| MB/s | Gbps | Description |
|---|---|---|
| 125 | 1 | |
| 1,250 | 10 | |
| 2,500 | 20 | |
| 3,125 | 25 | |
| 4,000 | 32 | PCIe Gen3x4 |
| 5,000 | 40 | |
| 8,000 | 64 | PCIe Gen4x4 |
| 10,000 | 80 | |
| 12,500 | 100 | |
| 16,000 | 128 | PCIe Gen5x4 |

- Disk
- クラスターの回復時間を考慮すると SSD であることが望ましい
- Pool 内で一番遅い Disk の速度が基準になる
- HDD を利用する場合は WAL/DB の設定を検討する
- Node あたりの Disk サイズが均等で使用量が分散されいていると最大パフォーマンスが出せる
- 4TB の Pool を作る場合 500GB 8 本と 1TB 4 本だと 500GB 8 本のほうが良い
- エンラープライズ SSD を使うべき
- 停電時の対策がされている
- TBW が高く壊れにくい
- 安定した I/O 性能を出せる
Monitor ¶
- Ceph Monitor はクラスターの高可用性を最新に維持する
- 最低 3 台で、大規模にならないなら 3 台以上不要
Manager ¶
- Ceph Manager は設定投入などのコントロールをになう
- RESTfull API や Dashboard を提供
OSD ¶
- OSD は SSD, HDD などの論理ディスク
- Ceph は OSD にブロックレベルで分割したデータを分散保存する
- OSD はクラスターで最小 3 つから
CephFS ¶
- Linux の EXT4 などと同様のファイルシステム
- Proxmox VE では
VZDump backup file,ISO image,Container templateの保存先になる
CephRBD ¶
- Rados Block Device、ブロックファイルシステム
- Proxmox VE では
Disk image,Containerの保存先になる
考慮事項 ¶
Ceph では OSD に書き込み、読み込みする動作が下記のようになっている。ため Read はどの Node でも高速に処理できるが書き込みは Server1, Server2, Server3 とあり VM が Server2 上の場合。 Server2 に書き込みされた後、 Server1, Server3 に複製され複製が完了した ACK を待って VM 上 OS に書き込み完了を報告する。
この時に利用されるネットワークは Cluster Network が存在しない場合 Public Network になり、存在する時は Cluster Network になる。そのため Disk のスループットを超える広帯域が望ましい。
Read
- RADOS に読み込みをリクエスト
- ローカル OSD がレスポンス
Write
- RADOS に書き込みをリクエスト, ローカル OSD に書き込み
- レプリカ OSD に転送し書き込み
- すべてのレプリカに書き込めたら、書込要求元 OSD に ACK を送信
- 書込完了をレスポンス
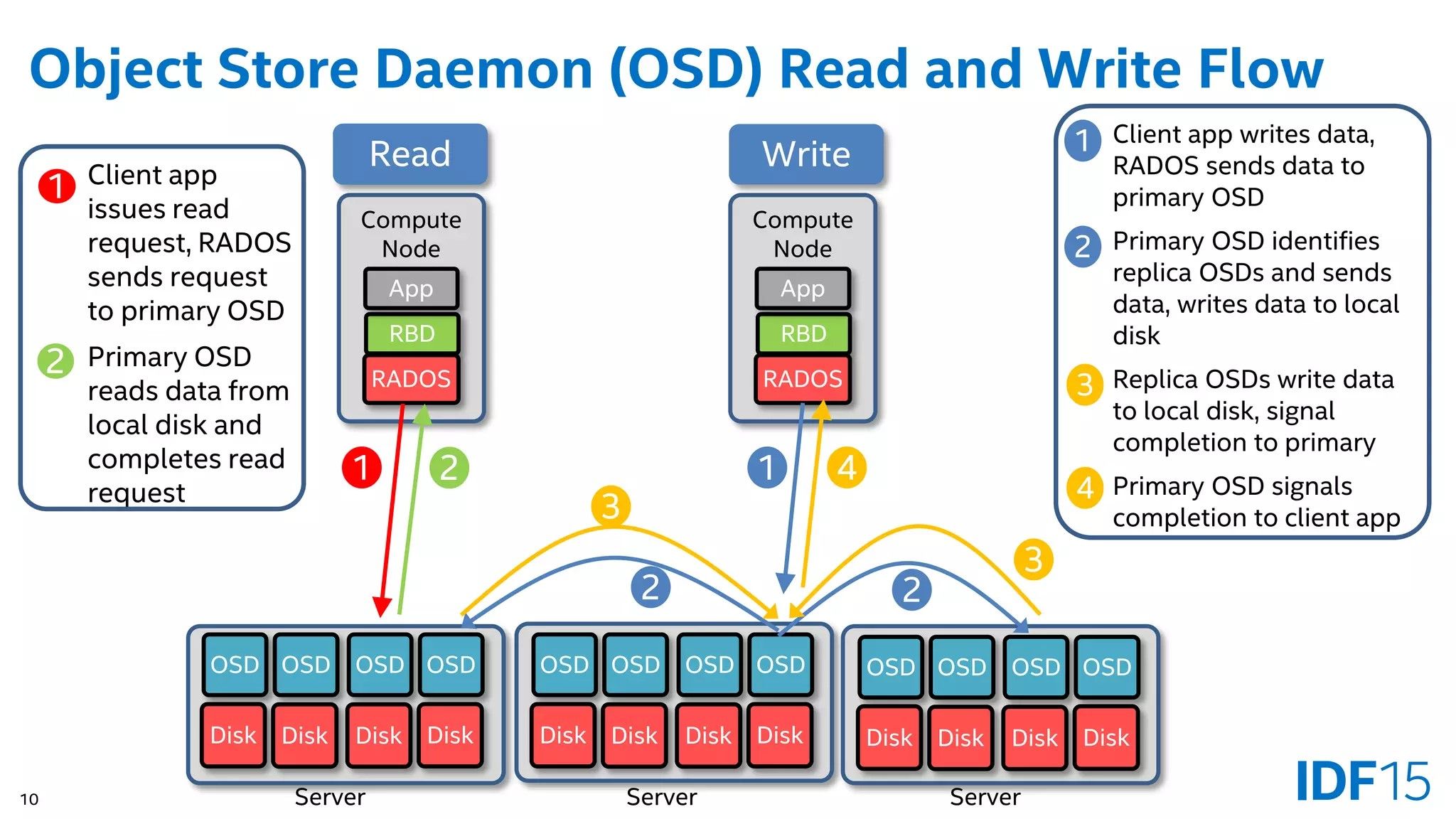

以上のことから、単体ストレージ(SSD, NVMe)の性能を最大限に発揮するには Write 性能の 2 倍ネットワーク帯域が必要になることを設計の基準とする必要がある。通常であれば冗長化に LACP などのリンクアグリゲーションを実施するので帯域幅 2 倍化はそれほど難しくない。
Troubleshooting ¶
VM の強制停止 ¶
BOIS での起動失敗などで強制停止する場合下記コマンドを Shell で実行、停止する21193 が停止したい VMID の場合。
| |
Disk の初期化 ¶
Disk のパーテーションをすべて削除してやり直すには下記解消する。
| |
ホスト,VM Console が開けない ¶
公式ドキュメント外から見たい ¶
通常 WebGUI から Help ボタンを押して表示されるドキュメントは自サーバーの物になるので検索も大変です。
通常であれば https://pve.proxmox.com/pve-docs/ に掲載されているため Google でよく下記の検索を多用しています。
| |
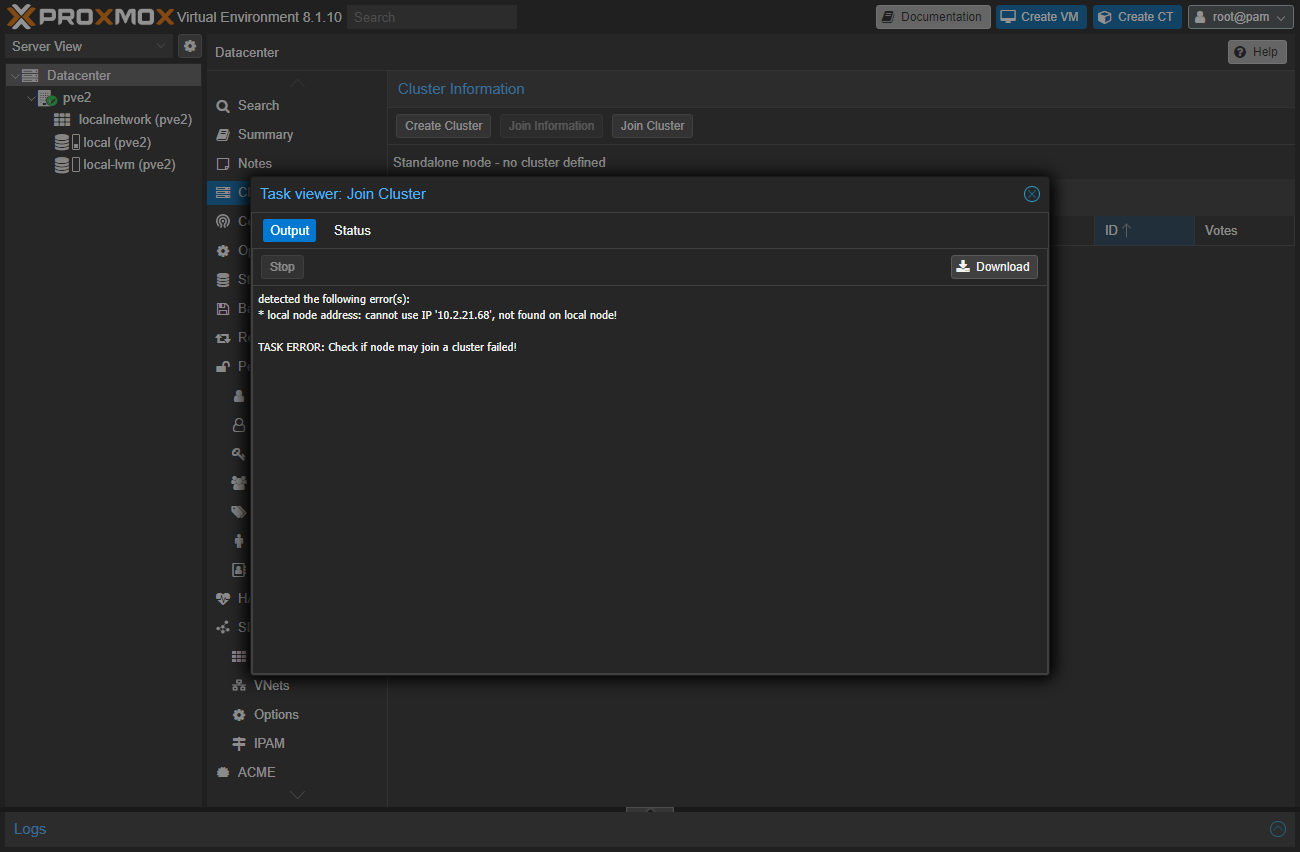
Cluster 登録出来ない ¶
| |
この場合 Interface の設定をインストール時と変更されていて不十分な状態。
2 箇所を変更しないといけません。
- Host >
System>Hostsに記載の IP を変更する - Host >
System>Networkで IP 変更
まとめ ¶
Proxmox VE の構成にはそれなりの知識と技能が必要です。
また構成などは社内の基盤を見ている人や DataCenter Network など多種多様な仕組み・考え方があるためよく調べて Scrap&Build で詰めていく必要があります。通常の仮想基盤選定の基準と代わりはあまりないですが HCI として導入する場合はしっかりと VM の I/O などを実データを集めて試験項目に加えることをオススメします。